2.5 实验数据处理过程¶
基于 ROOT 的核物理实验数据处理通常可分为两个主要阶段。第一阶段侧重于底层数据的解码、格式转换与初步整理;第二阶段则侧重于物理量的提取与高级物理分析。
💡 核心原则:模块化解耦与阶段性数据存储¶
整个分析流程应当拆分为若干个功能单一、职责明确的独立程序模块(如:1_unpack.cpp, 2_calibrate.cpp, 3_pid_cut.cpp, 4_physics.cpp)。在每完成一个关键逻辑步骤后,必须将处理结果保存为一个全新的 ROOT 文件(包含更新后的 TTree),并将其作为下一个环节的输入。
- 避免重复计算,大幅节省时间:物理分析是一个不断试错和迭代的过程(例如反复微调 Cut 边界、更改拟合区间)。如果每次调整末端参数,都从最原始的海量二进制文件开始重新运行程序,将消耗极大的时间成本。通过读取上一阶段生成的精简版 ROOT 文件作为当前阶段的输入,可以实现分析过程的秒级快速迭代。
- 降低代码耦合,提升容错率:不同层级的分析如果高度耦合,一旦某处逻辑(如某个探测器的刻度参数)发生更改,极易引发连锁错误,且排查困难(Debug 成本极高)。采用分步生成独立文件的方式,使得每个阶段的输入输出清晰明确,不仅便于逐级检查数据质量,也极大提高了代码的可维护性。
第一阶段:数据格式转换与初步整理¶
此阶段的目标是将探测器获取的信号读数转换为结构化的 ROOT 数据,并进行基础的清洗和校验。
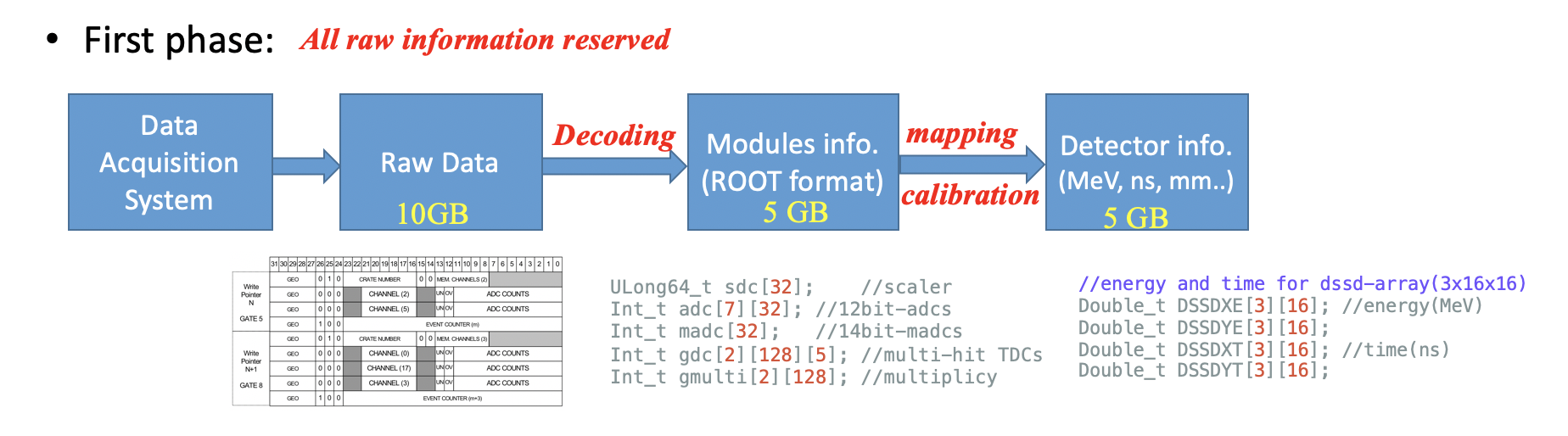
原始数据(raw data)¶
- 实验过程中由前端数据获取系统(DAQ)产生的二进制数据流保存到硬盘形成原始文件。原始数据通常由一系列的“数据块 (Data Block)”组成。每个数据块内包含来自不同电子学插件的数据,每个数据单元除了包含各个通道记录的探测器幅度值(如 ADC/TDC 读数)外,还包含通道地址、是否超界等状态描述字。
解码(decoding or mapping):¶
- 解码程序通过读取数据中每个插件的特定标识,按对应协议进行解码。随后,根据实验设定的“探测器信号-插件通道”对应表(Mapping Map),将上述硬件数据转换成每个物理事件中具体探测器的测量值。经过此步骤生成的文件通常称为原始 ROOT 文件 (Raw ROOT File)。
事件重构(event building):¶
- 根据探测器信号之间的时间逻辑关系,重新组织和对齐事件结构(具体算法机制见第 5 章)。
步骤二:参数完整性以及变量有效值区间¶
检查每一个实验参数的完整性,并根据数据实际情况选择合适的物理量计算方法:
- Case 1:在 PPAC 探测器实验中,若四个位置的时间信号正常,但阳极 (Anode) 信号异常(如接触不良或后端电子学故障),为了最大化利用有效数据,在位置信号的重建算法中,可放宽条件,不强制要求阳极信号的存在。
- Case 2:在中子探测器实验中,如果左侧的电荷量 $q_L$ 记录缺失,可通过时间信号 $t_L, t_R$ 以及右侧电荷量 $q_R$,利用经验公式重建总沉积能量 $Q$。
- 无效值标记:只对有效范围内的信号进行刻度处理。对于有效值范围外的数据(如低于台阶/Pedestal的噪声,或溢出/超界数据),应统一设定为与正常物理值有明显区分的特定标记值(例如
-999或-1),严禁将其作为有效零值参与物理计算。
步骤三:关键信息的直方图化存储 (Histograms)¶
在后续分析中,直接在 TTree 结构中通过 tree->Draw() 实时查看每个参数的分布极其耗时。因此,标准流程中除了生成包含 TTree 的 ROOT 文件(如 run001.root)外,还需将常用信息提取并以直方图(Histogram)的格式独立存储在另一个 ROOT 文件中(如 hist001.root)。
- 常用信息包括:ADC/TDC 各通道的原始能谱和时间谱、同类型探测器的 Hit 分布图、探测器间的二维关联谱(如 $\Delta E-E$, $TOF-\Delta E$)等。
利用目录结构组织直方图:
当直方图数量庞大时,可使用 TDirectoryFile 在 ROOT 文件内部创建类似文件系统的目录结构,以便于在 TBrowser 中快速浏览。
代码示例:在 ROOT 文件中创建目录并分类存储直方图
root -l mg18.root
root[0] new TBrowser
- 在左侧栏中双击文件名,在Draw Option栏中填入“colz”等绘图选项。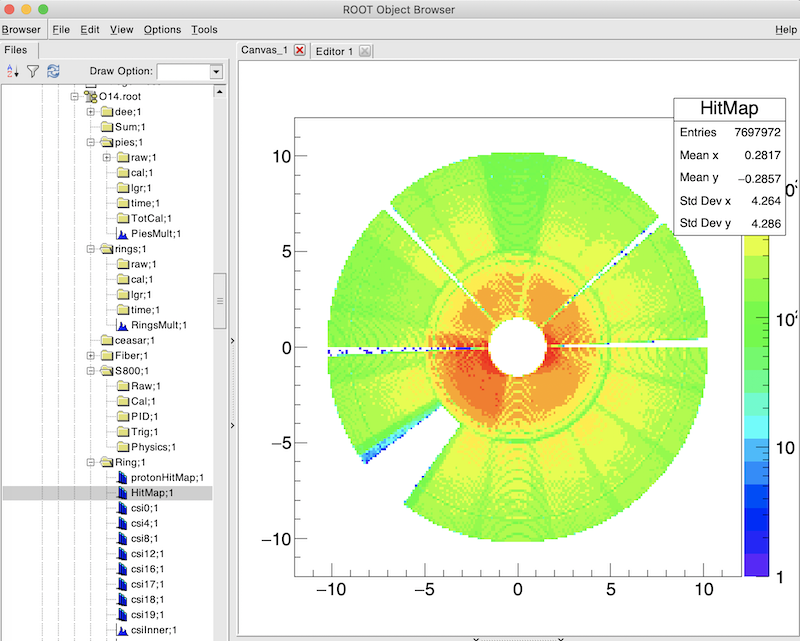
代码示例:在 ROOT 文件中创建目录并分类存储直方图¶
// 1. 创建用于存储直方图的 ROOT 文件
TFile *fout = new TFile("hist_test.root", "RECREATE");
// 2. 在根目录下创建一级目录 dir1 和 dir2
TDirectoryFile *dir1 = new TDirectoryFile("dir1", "ADC Spectra");
TDirectoryFile *dir2 = new TDirectoryFile("dir2", "TDC Spectra");
// 3. 在 dir1 下创建子目录 dir1sub
dir1->cd();
TDirectoryFile *dir1sub = new TDirectoryFile("dir1sub", "PPAC Detail");
// 4. 声明并初始化直方图 (注意在 new 之前切换到对应的目录)
TH1I *h0, *h1, *h2, *h1sub;
fout->cd(); // 回到根目录
h0 = new TH1I("h0", "Global Hist", 100, -3, 3);
dir1->cd(); // 进入 dir1
h1 = new TH1I("h1", "ADC Channel 1", 100, -3, 3);
dir1sub->cd(); // 进入子目录
h1sub = new TH1I("h1sub", "PPAC X pos", 100, -3, 3);
dir2->cd(); // 进入 dir2
h2 = new TH1I("h2", "TDC Channel 1", 100, -3, 3);
// 5. 填充数据 (实际分析中通常在 Event Loop 中进行)
h0->FillRandom("gaus", 10000);
h1->FillRandom("gaus", 10000);
h1sub->FillRandom("gaus", 10000);
h2->FillRandom("gaus", 10000);
// 6. 一次性将所有内存中的直方图按目录结构写入文件
fout->Write();
fout->Close();
- 形成如下目录结构
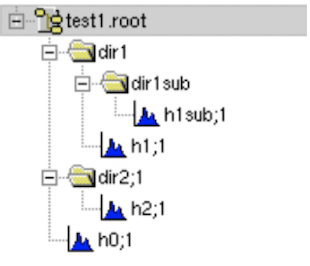
Read hist from the file¶
- root环境直接读取(见上图)
root -l hist_test.root
>new TBrowser
在左边树形目录结构中找到文件,鼠标点击进入目录结构,点击相应hist
- 代码读取
TFile *fin=new TFile("hist_test.root");
fin->ls();
TFile** hist_test.root TFile* hist_test.root KEY: TDirectoryFile dir1;1 ADC Spectra KEY: TDirectoryFile dir2;1 TDC Spectra KEY: TH1I h0;1 Global Hist
TH1I* h0a=(TH1I*) fin->Get("h0");
TH1I* h1a=(TH1I*) fin->Get("dir1/h1");
TH1I* h2a=(TH1I*) fin->Get("dir2/h2");
TH1I* h1suba=(TH1I*) fin->Get("dir1/dir1sub/h1sub");
h1suba->Draw();
c1->Draw();
Info in <TCanvas::MakeDefCanvas>: created default TCanvas with name c1
步骤四:实验参数一致性检验 (Drift Check)¶
由于探测器工作条件的变化(温度波动、噪声引入等)以及电子学参数的长期漂移,实验设备的增益或基线可能会随时间发生改变。 在进入正式物理刻度和设定数据切割条件(Cut)之前,必须确认基础参数的时间稳定性,并进行必要的动态修正。
- 文件内变化:观察参数值随事件编号(Event Number)或绝对时间戳(Timestamp)的变化趋势。
- 全局变化:观察参数的统计平均值(如某特征峰的位置、探测器效率、时间分辨)随 Run Number(文件编号)的宏观漂移情况。
下图显示某次实验中TDC值、位置探测器分辨、效率等参数随着文件号的变化。
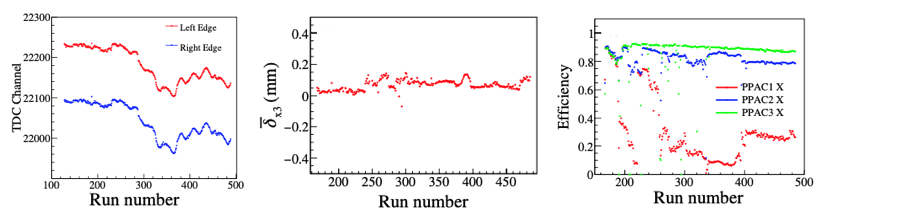
第二阶段:物理量提取与高级分析¶
第二阶段建立在第一阶段清洗和校准好的数据之上,主要包括物理量(如散射角、激发能、反应截面)的严格提取、物理条件的选取(Cut 应用)以及最终物理图谱的拟合等过程。
在此阶段,每个处理步骤都伴随着信息的深度提纯与压缩,无效本底被逐步剔除,数据文件的大小显著减小,程序在内存中的读取与分析速度大幅提升。完整的第二阶段通常包含以下几个核心环节:
1. 物理条件的选取(Cut 应用)¶
在提取最终物理观测量之前,必须从混杂的实验数据中精准筛选出目标反应事件,并最大程度压低本底。该过程通常通过在 ROOT 中施加多维度的条件切割(Cuts)来实现:
- 粒子鉴别(Particle Identification, PID):利用探测器组(如 $\Delta E-E$ 望远镜探测器或 $TOF-\Delta E$ 飞行时间系统),绘制二维关联散点图。不同电荷 $Z$ 和质量 $M$ 的同位素会在二维图上呈现清晰的“带状”分布。通过在 ROOT 中运用
TCutG类,沿着目标粒子的分布带绘制闭合多边形,生成 PID 筛选条件。 - 符合时间窗口选取(Time Window Cut):利用探测器之间的时间差(Time-of-Flight)设定严格的符合窗口(Prompt Window),从而甄别出真实的级联反应事件,并剔除由于高计数率导致的偶然符合本底(Random Coincidence)。
- 几何与运动学约束:排除打在探测器边缘死区或准直器上的无效事例,或利用反应前后的动量守恒逻辑,剔除不符合特定运动学规律的发散事件。
2. 物理量的严格提取(Kinematic Reconstruction)¶
经过 Cut 筛选后的纯净事件,其包含的变量仍是探测器坐标($X, Y, Z$)和校准后的能量(MeV)、时间(ns)。在此步骤中,需要利用相对论或经典运动学公式,将这些基础观测量转化为表征原子核性质的物理参量:
- 散射角提取(Scattering Angle):结合靶点位置与粒子在位置敏感探测器(如 PPAC、硅微条)上的击中坐标,利用空间几何关系计算出粒子出射的极角 $\theta$ 和方位角 $\phi$。
- 激发能与 Q 值重构(Excitation Energy):利用入射束流能量、出射粒子的动能与散射角 $\theta$,通过两体或多体运动学公式(Kinematics),逐事件(Event-by-Event)计算出反应体系的 $Q$ 值或剩余核的激发能 $E_x$。
3. 最终物理图谱的拟合与截面计算(Spectrum Fitting)¶
将提取出的物理量(如 $E_x$)投影为一维直方图后,即得到最终的物理图谱。后续的物理分析主要围绕图谱的解析展开:
- 信号拟合与本底扣除:利用 ROOT 中的
TF1类定义拟合函数。针对目标物理峰(如基态、激发态谱线),通常采用高斯函数(Gaussian)或布雷特-维格纳函数(Breit-Wigner)进行拟合;针对连续分布的物理本底,通常采用多项式或指数函数进行背景建模。通过拟合,可精确提取特定物理态的中心位置(对应能级)、展宽(对应寿命)以及净计数(Yield)。 - 反应截面提取(Cross Section):物理图谱中提取的净计数 $N$ 仅代表探测到的事例数。要获得具有普适物理意义的反应截面 $\sigma$,需结合实验中的束流积分流强、靶原子面密度,并引入探测器本征效率与几何接受度(通常由 Geant4 等蒙特卡罗软件模拟给出)进行严格的归一化修正。
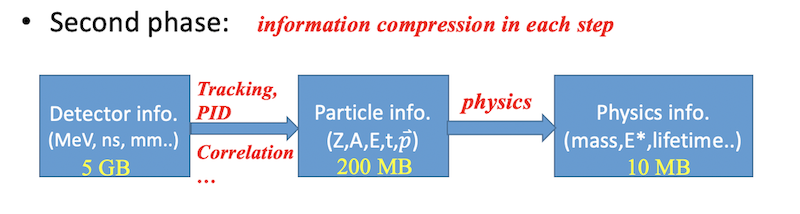
该阶段的一个显著特征是信息的高度浓缩:随着无效数据被剔除、多通道原始信号被重构为单一物理量,数据文件的大小会逐级显著减小,程序在内存中的读取和分析速度也会大幅提升。
以下是为你整理的、可直接作为讲义后续章节(例如 2.6 自动化数据处理:Bash 脚本实战教程)的完整 Tutorial 内容。
该教程紧密衔接前面的 C++ 编译程序,按由浅入深的逻辑,将真实实验中可预见的需求转化为标准化的 Bash 工作流。
Bash shell script tutorial¶
在核物理实验数据分析中,Bash 脚本则负责上层工作流的“自动化统筹”。
当我们将核心物理算法(如 2.4 节中的 ./tracking)编译为独立的可执行文件后,面对实验中产生的几十甚至上百个数据文件(Run),手动逐一输入命令显然是不切实际的。在真实的分析场景中,我们通常面临以下核心需求:
- 批量处理 (Batch Processing):能够一键循环处理连续的 Run。
- 动态传参 (Parameterization):允许通过命令行灵活指定要处理的 Run 范围。
- 容错机制 (Error Handling):自动检测文件是否损坏或缺失,避免程序崩溃。
- 后台挂机与日志 (Background & Logging):对于耗时数小时的分析任务,需支持断开终端连接后继续运行,并记录终端输出。
以下教程将分为 4 个层级,逐步建立数据分析自动化脚本。
Level 1:最基础的终端循环 (One-Liner)¶
如果你只需临时快速跑完 Run 1 到 Run 10,甚至不需要专门编写脚本文件,直接在 Linux 终端中输入一行命令即可完成批量提交:
for run in {1..10}; do ./tracking $run; done
- 语法解析:
for run in {1..10}:定义变量run,使其取值从 1 递增到 10。do ... done:Bash 的循环体结构,内部包含每次循环要执行的具体命令。$run:在 Bash 中,调用变量的值必须在变量名前加$符号。
Level 2:带参数的基础脚本 (变量与传参)¶
为了将执行逻辑固化并方便复用,通常创建一个 Shell 脚本文件(如 run_batch.sh)。为了避免每次修改代码内部的数字,我们需要引入命令行传参功能。
新建文件 run_batch.sh,写入以下内容:
#!/bin/bash
# 第一行称为 Shebang,告知系统使用 bash 解释器来运行此脚本
# $1 表示用户输入的第一个参数(起始Run),$2 表示第二个参数(结束Run)
START=$1
END=$2
echo ">>> 准备分析从 Run $START 到 Run $END 的数据..."
# 使用 seq 命令生成从 START 到 END 的连续数字序列
for run in $(seq $START $END); do
echo "--- 正在处理 Run $run ---"
./tracking $run
done
echo ">>> 所有任务执行完毕!"
- 使用方法:
- 赋予脚本可执行权限:
chmod +x run_batch.sh - 运行脚本并传入起止 Run 号:
./run_batch.sh 10 20
- 赋予脚本可执行权限:
Level 3:复杂数据分析脚本 (格式化与容错处理)¶
在真实实验中,数据文件通常带有补零格式(如 run001.root 而非 run1.root),且常常会因为各种原因跳过某些 Run。此时,我们需要在脚本中加入字符串格式化与文件存在性检测。
更新 run_batch.sh,加入容错逻辑与目录管理:
#!/bin/bash
# 1. 参数数量安全校验
if [ "$#" -ne 2 ]; then
echo "用法错误! 正确格式: ./run_batch.sh <开始Run号> <结束Run号>"
exit 1
fi
START=$1
END=$2
IN_DIR="./data" # 假设原始数据存放在 data 目录下
OUT_DIR="./output" # 定义输出归档目录
# 2. 创建输出目录(-p 表示如果目录已存在则不报错)
mkdir -p $OUT_DIR
for run in $(seq $START $END); do
# 3. 核心技巧:使用 printf 将数字 1 格式化为 001
RUN_FMT=$(printf "%03d" $run)
FILE_NAME="f8ppac${RUN_FMT}.root"
# 4. 容错检测:-f 判断原始文件是否存在
if [ ! -f "${IN_DIR}/${FILE_NAME}" ]; then
echo "警告: 找不到文件 ${IN_DIR}/${FILE_NAME},自动跳过..."
continue # 跳过本次循环,直接进入下一个 Run
fi
# 5. 执行核心 C++ 分析程序
echo ">>> 开始处理 Run ${RUN_FMT} ..."
./tracking $run
# 6. 分析完成后,将生成的结果文件移动到统一的输出目录
# 注意:需确保 main.cpp 中生成的输出文件名规律为 out001.root
if [ -f "out${RUN_FMT}.root" ]; then
mv "out${RUN_FMT}.root" $OUT_DIR/
echo " 已将结果归档至 ${OUT_DIR}/out${RUN_FMT}.root"
fi
done
Level 4:服务器上的后台挂机与日志监控 (nohup)¶
处理海量实验数据通常需要运行数小时。如果直接在终端运行 ./run_batch.sh 1 100,一旦电脑休眠、断网或 SSH 终端连接断开,正在运行的程序会被 Linux 系统强制终止(Kill)。
终极解决方案:使用 nohup (No Hang Up) 与后台符 &。
在终端输入以下完整命令:
nohup ./run_batch.sh 1 100 > analysis.log 2>&1 &
- 语法解析:
nohup:忽略系统的挂断信号,即使关闭终端窗口,程序也会继续在服务器上运行。> analysis.log:将原本要在屏幕上打印的所有标准输出(如 C++ 中的std::cout),重定向保存到analysis.log文本文件中。2>&1:将标准错误(2,如std::cerr的报错信息)一并合并到标准输出(1)中,确保报错日志不丢失。&:放在命令最末尾,表示将该任务放入后台(Background)执行。按下回车后,终端立刻恢复自由状态,你可以继续输入其他命令。
如何实时监控后台进度? 虽然程序在后台静默运行,但你可以随时查看日志文件的最新动态以监控进度:
# -f (follow) 选项会实时追踪并刷新日志文件的末尾输出
tail -f analysis.log
(查看完毕后,按 Ctrl + C 即可退出日志监控,这不会影响后台程序的运行。)